(7)Elasticsearch
1 Elasticsearch 有哪些基本概念?
- (1)index 索引:索引类似于mysql 中的数据库,Elasticesearch 中的索引是存在数据的地方,包含了一堆有相似结构的文档数据。
- (2)type 类型:类型是用来定义数据结构,可以认为是 mysql 中的一张表,type 是 index 中的一个逻辑数据分类
- (3)document 文档:类似于 MySQL 中的一行,不同之处在于 ES 中的每个文档可以有不同的字段,但是对于通用字段应该具有相同的数据类型,文档是es中的最小数据单元,可以认为一个文档就是一条记录。
- (4)Field 字段:Field是Elasticsearch的最小单位,一个document里面有多个field
- (5)shard 分片:单台机器无法存储大量数据,ES 可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。
- (6)replica 副本:任何一个服务器随时可能故障或宕机,此时 shard 可能会丢失,因此可以为每个 shard 创建多个 replica 副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个 shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
2 Elasticsearch的使用场景是什么?
- 全文检索和数据分析:Elasticsearch是一款分布式的全文搜索引擎,适用于监控面板、日志实时分析、搜索服务、数据分析、数据监控等场景
- 后端存储:在新项目中,可以考虑将Elasticsearch作为唯一的数据存储,简化设计并提供持久存储和统计功能
- 系统扩展:对于复杂查询、事务需求或需要添加检索服务的现有系统,可以将Elasticsearch作为新组件添加到系统中
- 日志数据:帮助企业从复杂的日志数据中提取信息,优化业务流程和应用性能
3 详细说说什么是倒排索引?
倒排索引是一种用于全文搜索的数据结构,将文档中的每个单词映射到包含该单词的所有文档的列表中,然后用该列表替换单词。这种索引结构的核心思想是从文档到单词的正向索引转变为从单词到文档的反向索引。倒排索引通过记录每个单词在哪些文档中出现,实现了快速检索包含特定单词的文档列表,从而加速搜索过程。
倒排索引由两部分组成:词典和倒排列表。词典包含了文档集合中出现过的所有单词,每个单词指向包含该单词的文档列表。倒排列表则记录了每个单词在哪些文档中出现,以及出现位置、频率等相关信息。这种结构支持快速定位包含特定单词的文档,实现高效的搜索和检索。
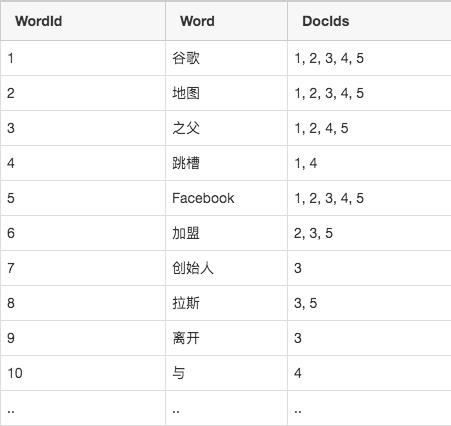
倒排索引具有以下特点和优势:
- 灵活的扩展性:支持横向扩展,可以水平分割和复制数据,提高搜索效率。
- 支持分词:将连续字母或数字序列划分为有意义的词组或单个词汇,用于构建更精确的搜索结果。
- 支持位置信息:记录每个单词在句子中的位置,支持短语搜索和文本摘要等功能。
倒排索引是一种基于单词的文本搜索和匹配算法,能够显著加速搜索引擎的查询速度,并提升用户体验。
4 Elasticsearch是如何避免脑裂现象?
Elasticsearch在选举主节点上产生分歧,产生多个主节点,从而使集群分裂,使得集群处于异常状态,这个现象叫做脑裂。脑裂问题其实就是同一个集群的不同节点对于整个集群的状态有不同的理解,导致操作错乱,类似于精神分裂。
- 1)当集群中 master 候选节点数量不小于3个时(node.master: true),可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes),设置超过所有候选节点一半以上来解决脑裂问题,即设置为 (N/2)+1。
- 2)当集群 master 候选节点只有两个时,这种情况是不合理的,最好把另外一个node.master改成false。如果我们不改节点设置,还是套上面的(N/2)+1公式,此时discovery.zen.minimum_master_nodes应该设置为2。这就出现一个问题,两个master备选节点,只要有一个挂,就选不出master了。
5 Elasticsearch 索引文档的过程是什么?
- 当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 MemoryBuffer,然后定时(默认是每隔 1 秒)写入到 Filesystem Cache,这个从 MomeryBuffer 到 Filesystem Cache 的过程就叫做 refresh;
- 某些情况下,存在 Momery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
- 在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512M)时。
6 Elasticsearch 如何聚合亿级数据?
Elasticsearch 提供的首个近似聚合是 cardinality 度量。它提供一个字段的基数,即该字段的 distinct 或者unique 值的数目。它是基于 HLL 算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的。可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关
7 在高并发情况下,Elasticsearch 如何保证读写一致?
- 通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
- 对于写操作,一致性级别支持 quorum/one/all,默认为 quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
- 对于读操作,可以设置 replication 为 sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置 replication 为 async 时,也可以通过设置搜索请求参数_preference 为 primary 来查询主分片,确保文档是最新版本。
8 说说 Elasticsearch 的搜索流程?
搜索被执行成一个两阶段过程,即 Query Then Fetch:
- Query阶段
客户端发送请求到 coordinate node,协调节点将搜索请求广播到所有的 primary shard 或 replica shard。每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,由协调节点及逆行数据的合并、排序、分页等操作,产出最终结果。
- Fetch阶段
协调节点根据 doc id 去各个节点上查询实际的 document 数据,由协调节点返回结果给客户端。coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。接收请求的 node 返回 document 给 coordinate node 。coordinate node 返回 document 给客户端。Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document frequency,这个评分更准确,但是性能会变差。
9 Elasticsearch 深度分页的解决方案?
Elasticsearch 的 From/Size 方式提供了基本的分页的功能。每次有序的查询都会在每个分片中执行单独的查询,然后进行数据的二次排序,而这个二次排序的过程是发生在heap中的。单次查询的数量越大,堆内存中汇总的数据也就越多,对内存的压力也就越大。单次查询的数据量取决于查询的是第几条数据,而不是查询了几条数据,比如查询的是第10001-10100这一百条数据,ES必须将前10100全部取出进行二次查询。如果查询的数据排序越靠后,就越容易导致OOM(Out Of Memory)情况的发生,频繁的深分页查询会导致频繁的FGC。解决深度分页有4个方案:
- max_result_window
max_result_window是分页返回的最大数值,默认值为10000。max_result_window本身是对JVM的一种保护机制,通过设定一个合理的阈值,避免分页查询时由于单页数据过大而导致OOM。
- Scroll
Scroll可以理解为关系型数据库里的游标,因此 scroll并不适合用来做实时搜索,而更适合用于后台批处理任务,比如群发。scroll相当于维护了一份当前索引段的快照信息,这个快照信息是你执行这个scroll查询时的快照。在这个查询后的任何新索引进来的数据,都不会在这个快照中查询到。但是scroll相对于from和size,不是查询所有数据然后剔除不要的部分,而是记录一个读取的位置,保证下一次快速继续读取。
- Sliced Scroll
每个Scroll请求,可以分成多个Slice请求,可以理解为切片,各Slice独立并行,比用Scroll遍历要快很多倍。
POST /index/type/_search?scroll=1m
{
"query": { "match_all": {}},
"slice": {
"id": 0,
"max": 5
}
}
POST ip:port/index/type/_search?scroll=1m
{
"query": { "match_all": {}},
"slice": {
"id": 1,
"max": 5
}
}
上边的示例可以单独请求两块数据,最终五块数据合并的结果与直接scroll scan相同。其中max是分块数,id是第几块。官方文档中建议max的值不要超过shard的数量,否则可能会导致内存爆炸。
- search_after
从7.X版本开始,可以使用SEARCH_AFTER参数通过上一页中的一组排序值检索下一页命中。
使用SEARCH_AFTER需要多个具有相同查询和排序值的搜索请求。如果这些请求之间发生刷新,则结果的顺序可能会更改,从而导致页面之间的结果不一致。为防止出现这种情况,您可以创建一个时间点(PIT)来在搜索过程中保留当前索引状态。
POST /my-index-000001/_pit?keep_alive=1m
返回一个PIT ID:
{
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA=="
}
在搜索请求中指定PIT:
GET /_search
{
"size": 10000,
"query": {
"match" : {
"user.id" : "elkbee"
}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",
"keep_alive": "1m"
},
"sort": [
{"@timestamp": {"order": "asc", "format": "strict_date_optional_time_nanos", "numeric_type" : "date_nanos" }}
]
}
Scroll和search_after原理基本相同,他们都采用了游标的方式来进行深分页。这种方式虽然能够一定程度上解决深分页问题。但是,它们并不是深分页问题的终极解决方案,必须要避免深分页问题。
对于Scroll,无可避免的要维护scroll_id和历史快照,并且,还必须保证scroll_id的存活时间,这对服务器是一个巨大的负荷。
对于Search_After,如果允许用户大幅度跳转页面,会导致短时间内频繁的搜索动作,这样的效率非常低下,这也会增加服务器的负荷,同时,在查询过程中,索引的增删改会导致查询数据不一致或者排序变化,造成结果不准确。Search_After本身就是一种业务折中方案,它不允许指定跳转到页面,而只提供下一页的功能。
10 Elasticsearch 在部署时,Linux 的设置有哪些优化方法?
- 关闭缓存swap。大多数操作系统会将内存使用到文件系统缓存,会将应用程序未用到的内存交换出去。会导致jvm的堆内存交换到磁盘上。交换会导致性能问题。会导致内存垃圾回收延长。会导致集群节点响应时间变慢,或者从集群中断开
- 堆内存设置为 Min(节点内存/2, 32GB)
- 设置最大文件句柄数
11 说说Elasticsearch 更新和删除文档的过程?
Elasticsearch 的文档是不可变的,删除和更新都是写操作,不能被删除或者改动以展示其变更。磁盘上的每个段都有一个相应的 .del 文件。当删除请求发送后,文档并没有真的被删除,而是在 .del 文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del 文件中被标记为删除的文档将不会被写入新段。在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del 文件中被标记为删除,新版本的文档被索引到一个新段。
参考
https://zhuanlan.zhihu.com/p/586071616
https://zhuanlan.zhihu.com/p/529387057
https://zhuanlan.zhihu.com/p/646647668
https://zhuanlan.zhihu.com/p/675559003
https://zhuanlan.zhihu.com/p/647451683
https://zhuanlan.zhihu.com/p/87686321
https://www.jianshu.com/p/179fd8bc944b