4 Deployment
4 Deployment
在生产环境中,我们基本上不会直接管理 pod,我们需要 kubernetes 来帮助我们来完成一些自动化操作,例如自动扩容或者自动升级版本。可以想象在生产环境中,我们手动部署了 10 个 hellok8s:v1 的 pod,这个时候我们需要升级成 hellok8s:v2 版本,我们难道需要一个一个的将 hellok8s:v1 的 pod 手动升级吗?
这个时候就需要我们来看 kubeates 的另外一个资源 deployment,来帮助我们管理 pod。
扩容
首先可以创建一个 deployment.yaml 的文件。来管理 hellok8s pod。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-deployment
spec:
replicas: 1
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: guangzhengli/hellok8s:v1
name: hellok8s-container
其中 kind 表示我们要创建的资源是 deployment 类型, metadata.name 表示要创建的 deployment 的名字,这个名字需要是唯一的。
在 spec 里面表示,首先 replicas 表示的是部署的 pod 副本数量,selector 里面表示的是 deployment 资源和 pod 资源关联的方式,这里表示 deployment 会管理 (selector) 所有 labels=hellok8s 的 pod。
template 的内容是用来定义 pod 资源的,你会发现和作业一:Hellok8s Pod 资源的定义是差不多的,唯一的区别是我们需要加上 metadata.labels 来和上面的 selector.matchLabels 对应起来。来表明 pod 是被 deployment 管理,不用在template 里面加上 metadata.name 是因为 deployment 会主动为我们创建 pod 的唯一name。
接下来输入下面的命令,可以创建 deployment 资源。通过 get 和 delete pod 命令,我们会初步感受 deployment 的魅力。每次创建的 pod 名称都会变化,某些命令记得替换成你的 pod 的名称
kubectl apply -f deployment.yaml
kubectl get deployments
#NAME READY UP-TO-DATE AVAILABLE AGE
#hellok8s-deployment 1/1 1 1 39s
kubectl get pods
#NAME READY STATUS RESTARTS AGE
#hellok8s-deployment-77bffb88c5-qlxss 1/1 Running 0 119s
kubectl delete pod hellok8s-deployment-77bffb88c5-qlxss
#pod "hellok8s-deployment-77bffb88c5-qlxss" deleted
kubectl get pods
#NAME READY STATUS RESTARTS AGE
#hellok8s-deployment-77bffb88c5-xp8f7 1/1 Running 0 18s
我们会发现一个有趣的现象,当手动删除一个 pod 资源后,deployment 会自动创建一个新的 pod,这和我们之前手动创建 pod 资源有本质的区别!这代表着当生产环境管理着成千上万个 pod 时,我们不需要关心具体的情况,只需要维护好这份 deployment.yaml 文件的资源定义即可。
接下来我们通过自动扩容来加深这个知识点,当我们想要将 hellok8s:v1 的资源扩容到 3 个副本时,只需要将 replicas 的值设置成 3,接着重新输入 kubectl apply -f deployment.yaml 即可。如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-deployment
spec:
replicas: 3
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: guangzhengli/hellok8s:v1
name: hellok8s-container
可以在 kubectl apply 之前通过新建窗口执行 kubectl get pods --watch 命令来观察 pod 启动和删除的记录,想要减少副本数时也很简单,你可以尝试将副本数随意增大或者缩小,再通过 watch 来观察它的状态。
升级版本
我们接下来尝试将所有 v1 版本的 pod 升级到 v2 版本。首先我们需要构建一份 hellok8s:v2 的版本镜像。唯一的区别就是字符串替换成了 [v2] Hello, Kubernetes!。
package main
import (
"io"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request) {
io.WriteString(w, "[v2] Hello, Kubernetes!")
}
func main() {
http.HandleFunc("/", hello)
http.ListenAndServe(":3000", nil)
}
将 hellok8s:v2 推到 DockerHub 仓库中。
docker build . -t guangzhengli/hellok8s:v2
docker push guangzhengli/hellok8s:v2
接着编写 v2 版本的 deployment 资源文件。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-deployment
spec:
replicas: 3
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: guangzhengli/hellok8s:v2
name: hellok8s-container
kubectl apply -f deployment.yaml
# deployment.apps/hellok8s-deployment configured
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# hellok8s-deployment-66799848c4-kpc6q 1/1 Running 0 3s
# hellok8s-deployment-66799848c4-pllj6 1/1 Running 0 3s
# hellok8s-deployment-66799848c4-r7qtg 1/1 Running 0 3s
kubectl port-forward hellok8s-deployment-66799848c4-kpc6q 3000:3000
# Forwarding from 127.0.0.1:3000 -> 3000
# Forwarding from [::1]:3000 -> 3000
# open another terminal
curl http://localhost:3000
# [v2] Hello, Kubernetes!
你也可以输入 kubectl describe pod hellok8s-deployment-66799848c4-kpc6q 来看是否是 v2 版本的镜像。
Rolling Update(滚动更新)
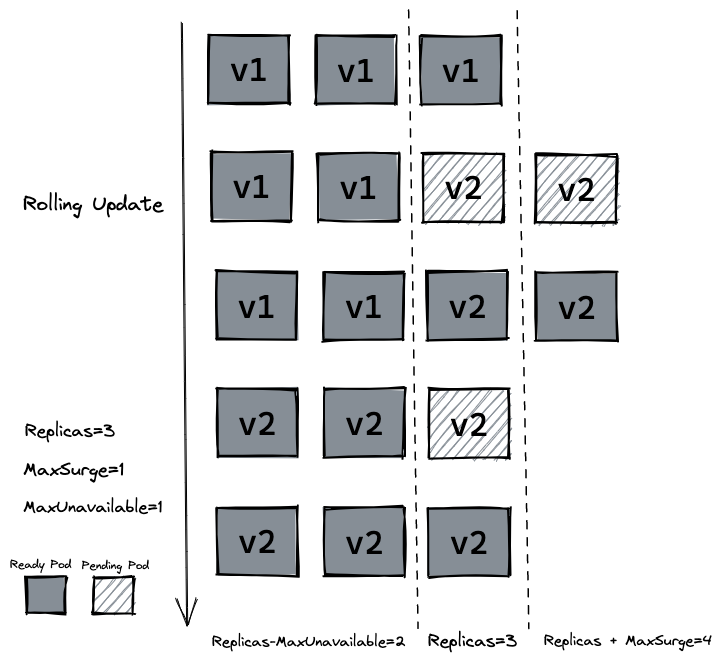
如果我们在生产环境上,管理着多个副本的 hellok8s:v1 版本的 pod,我们需要更新到 v2 的版本,像上面那样的部署方式是可以的,但是也会带来一个问题,就是所有的副本在同一时间更新,这会导致我们 hellok8s 服务在短时间内是不可用的,因为所有 pod 都在升级到 v2 版本的过程中,需要等待某个 pod 升级完成后才能提供服务。
这个时候我们就需要滚动更新 (rolling update),在保证新版本 v2 的 pod 还没有 ready 之前,先不删除 v1 版本的 pod。
在 deployment 的资源定义中, spec.strategy.type 有两种选择:
- RollingUpdate: 逐渐增加新版本的 pod,逐渐减少旧版本的 pod。
- Recreate: 在新版本的 pod 增加前,先将所有旧版本 pod 删除。
大多数情况下我们会采用滚动更新 (RollingUpdate) 的方式,滚动更新又可以通过 maxSurge 和 maxUnavailable 字段来控制升级 pod 的速率,具体可以详细看官网定义。:
- maxSurge: 最大峰值,用来指定可以创建的超出期望 Pod 个数的 Pod 数量。
- maxUnavailable: 最大不可用,用来指定更新过程中不可用的 Pod 的个数上限。
我们先输入命令回滚我们的 deployment,输入 kubectl describe pod 会发现 deployment 已经把 v2 版本的 pod 回滚到 v1 的版本。
kubectl rollout undo deployment hellok8s-deployment
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# hellok8s-deployment-77bffb88c5-cvm5c 1/1 Running 0 39s
# hellok8s-deployment-77bffb88c5-lktbl 1/1 Running 0 41s
# hellok8s-deployment-77bffb88c5-nh82z 1/1 Running 0 37s
kubectl describe pod hellok8s-deployment-77bffb88c5-cvm5c
# Image: guangzhengli/hellok8s:v1
除了上面的命令,还可以用 history 来查看历史版本,--to-revision=2 来回滚到指定版本。
kubectl rollout history deployment hellok8s-deployment
kubectl rollout undo deployment/hellok8s-deployment --to-revision=2
接着设置 strategy=rollingUpdate , maxSurge=1 , maxUnavailable=1 和 replicas=3 到 deployment.yaml 文件中。这个参数配置意味着最大可能会创建 4 个 hellok8s pod (replicas + maxSurge),最小会有 2 个 hellok8s pod 存活 (replicas - maxUnavailable)。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-deployment
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
replicas: 3
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: guangzhengli/hellok8s:v2
name: hellok8s-container
存活探针 (livenessProb)
存活探测器来确定什么时候要重启容器。 例如,存活探测器可以探测到应用死锁(应用程序在运行,但是无法继续执行后面的步骤)情况。 重启这种状态下的容器有助于提高应用的可用性,即使其中存在缺陷。-- LivenessProb
在生产中,有时候因为某些 bug 导致应用死锁或者线程耗尽了,最终会导致应用无法继续提供服务,这个时候如果没有手段来自动监控和处理这一问题的话,可能会导致很长一段时间无人发现。kubelet 使用存活探测器 (livenessProb) 来确定什么时候要重启容器。
接下来我们写一个 /healthz 接口来说明 livenessProb 如何使用。 /healthz 接口会在启动成功的 15s 内正常返回 200 状态码,在 15s 后,会一直返回 500 的状态码。
package main
import (
"fmt"
"io"
"net/http"
"time"
)
func hello(w http.ResponseWriter, r *http.Request) {
io.WriteString(w, "[v2] Hello, Kubernetes!")
}
func main() {
started := time.Now()
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Since(started)
if duration.Seconds() > 15 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
})
http.HandleFunc("/", hello)
http.ListenAndServe(":3000", nil)
}
# Dockerfile
FROM golang:1.16-buster AS builder
RUN mkdir /src
ADD . /src
WORKDIR /src
RUN go env -w GO111MODULE=auto
RUN go build -o main .
FROM gcr.io/distroless/base-debian10
WORKDIR /
COPY --from=builder /src/main /main
EXPOSE 3000
ENTRYPOINT ["/main"]
Dockerfile 的编写和原来保持一致,我们把 tag 修改为 liveness 并推送到远程仓库。
docker build . -t guangzhengli/hellok8s:liveness
docker push guangzhengli/hellok8s:liveness
最后编写 deployment 的定义,这里使用存活探测方式是使用 HTTP GET 请求,请求的是刚才定义的 /healthz 接口,periodSeconds 字段指定了 kubelet 每隔 3 秒执行一次存活探测。 initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 3 秒。如果服务器上 /healthz 路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。 如果处理程序返回失败代码,则 kubelet 会杀死这个容器并将其重启。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-deployment
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
replicas: 3
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: guangzhengli/hellok8s:liveness
name: hellok8s-container
livenessProbe:
httpGet:
path: /healthz
port: 3000
initialDelaySeconds: 3
periodSeconds: 3
通过 get 或者 describe 命令可以发现 pod 一直处于重启当中。
kubectl apply -f deployment.yaml
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# hellok8s-deployment-5995ff9447-d5fbz 1/1 Running 4 (6s ago) 102s
# hellok8s-deployment-5995ff9447-gz2cx 1/1 Running 4 (5s ago) 101s
# hellok8s-deployment-5995ff9447-rh29x 1/1 Running 4 (6s ago) 102s
kubectl describe pod hellok8s-68f47f657c-zwn6g
# ...
# ...
# ...
# Events:
# Type Reason Age From Message
# ---- ------ ---- ---- -------
# Normal Scheduled 12m default-scheduler Successfully assigned default/hellok8s-deployment-5995ff9447-rh29x to minikube
# Normal Pulled 11m (x4 over 12m) kubelet Container image "guangzhengli/hellok8s:liveness" already present on machine
# Normal Created 11m (x4 over 12m) kubelet Created container hellok8s-container
# Normal Started 11m (x4 over 12m) kubelet Started container hellok8s-container
# Normal Killing 11m (x3 over 12m) kubelet Container hellok8s-container failed liveness probe, will be restarted
# Warning Unhealthy 11m (x10 over 12m) kubelet Liveness probe failed: HTTP probe failed with statuscode: 500
# Warning BackOff 2m41s (x36 over 10m) kubelet Back-off restarting failed container
就绪探针 (readiness)
就绪探测器可以知道容器何时准备好接受请求流量,当一个 Pod 内的所有容器都就绪时,才能认为该 Pod 就绪。 这种信号的一个用途就是控制哪个 Pod 作为 Service 的后端。 若 Pod 尚未就绪,会被从 Service 的负载均衡器中剔除。-- ReadinessProb
在生产环境中,升级服务的版本是日常的需求,这时我们需要考虑一种场景,即当发布的版本存在问题,就不应该让它升级成功。kubelet 使用就绪探测器可以知道容器何时准备好接受请求流量,当一个 pod 升级后不能就绪,即不应该让流量进入该 pod,在配合 rollingUpate 的功能下,也不能允许升级版本继续下去,否则服务会出现全部升级完成,导致所有服务均不可用的情况。
这里我们把服务回滚到 hellok8s:v2 的版本,可以通过上面学习的方法进行回滚。
kubectl rollout undo deployment hellok8s-deployment --to-revision=2
这里我们将应用的 /healthz 接口直接设置成返回 500 状态码,代表该版本是一个有问题的版本。
package main
import (
"io"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request) {
io.WriteString(w, "[v2] Hello, Kubernetes!")
}
func main() {
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
w.WriteHeader(500)
})
http.HandleFunc("/", hello)
http.ListenAndServe(":3000", nil)
}
在 build 阶段我们将 tag 设置为 bad,打包后 push 到远程仓库。
docker build . -t guangzhengli/hellok8s:bad
docker push guangzhengli/hellok8s:bad
接着编写 deployment 资源文件,Probe 有很多配置字段,可以使用这些字段精确地控制就绪检测的行为:
initialDelaySeconds:容器启动后要等待多少秒后才启动存活和就绪探测器, 默认是 0 秒,最小值是 0。periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。successThreshold:探测器在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。failureThreshold:当探测失败时,Kubernetes 的重试次数。 对存活探测而言,放弃就意味着重新启动容器。 对就绪探测而言,放弃意味着 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-deployment
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
replicas: 3
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: guangzhengli/hellok8s:bad
name: hellok8s-container
readinessProbe:
httpGet:
path: /healthz
port: 3000
initialDelaySeconds: 1
successThreshold: 5
通过 get 命令可以发现两个 pod 一直处于还没有 Ready 的状态当中,通过 describe 命令可以看到是因为 Readiness probe failed: HTTP probe failed with statuscode: 500 的原因。又因为设置了最小不可用的服务数量为maxUnavailable=1,这样能保证剩下两个 v2 版本的 hellok8s 能继续提供服务!
kubectl apply -f deployment.yaml
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# hellok8s-deployment-66799848c4-8xzsz 1/1 Running 0 102s
# hellok8s-deployment-66799848c4-m9dl5 1/1 Running 0 102s
# hellok8s-deployment-9c57c7f56-rww7k 0/1 Running 0 26s
# hellok8s-deployment-9c57c7f56-xt9tw 0/1 Running 0 26s
kubectl describe pod hellok8s-deployment-9c57c7f56-rww7k
# Events:
# Type Reason Age From Message
# ---- ------ ---- ---- -------
# Normal Scheduled 74s default-scheduler Successfully assigned default/hellok8s-deployment-9c57c7f56-rww7k to minikube
# Normal Pulled 73s kubelet Container image "guangzhengli/hellok8s:bad" already present on machine
# Normal Created 73s kubelet Created container hellok8s-container
# Normal Started 73s kubelet Started container hellok8s-container
# Warning Unhealthy 0s (x10 over 72s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 500