1.4 线性表-哈希表
哈希表定义
比较常用两种数据结构:数组和链表,主要区别在于数据是否存储在连续的地址空间中,但无论是哪一种,我们从外部访问的时候,都是访问的第一个元素或节点的地址,这就造成了如果需要查找一个值或记录,我们要从头开始,遍历整个数组或链表,直到找到该值或查找失败。因此无论是数组还是链表,查找的平均时间复杂度都为 Θ(n)。
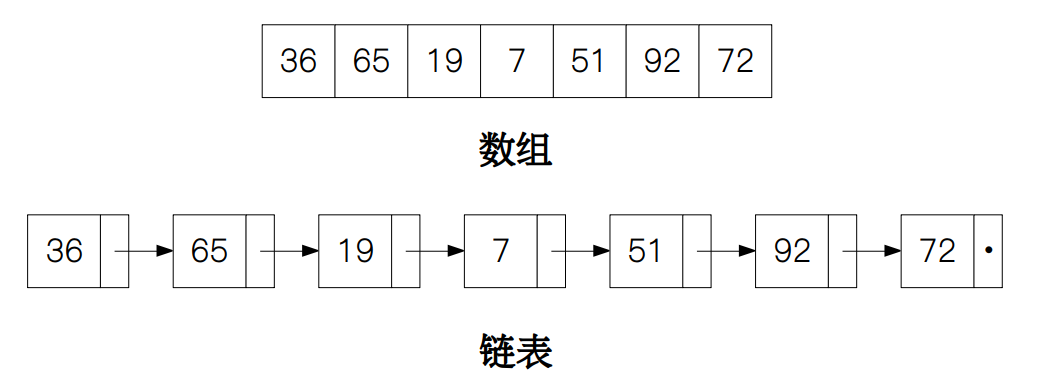
既然查找一个元素都需要先获取该数据结构头部的地址,那么我们可不可以直接获取一个元素对应的存储地址呢?这样我每输入一个要查找的元素就会对应输出该元素对应的地址,查找效率不就上去了吗?答案肯定的,但这我们里需要用到一种特殊的数据结构:哈希表。
哈希表(hash table)也叫散列表。它是用来存储经过哈希操作后的数据,每一个数据都对应一个地址,供外部程序来访问。当需要查找一个值key时,我们需要用一个函数H(key)将key映射到一个特定的地址address上,然后比较该地址上的值来判断是否查找成功。
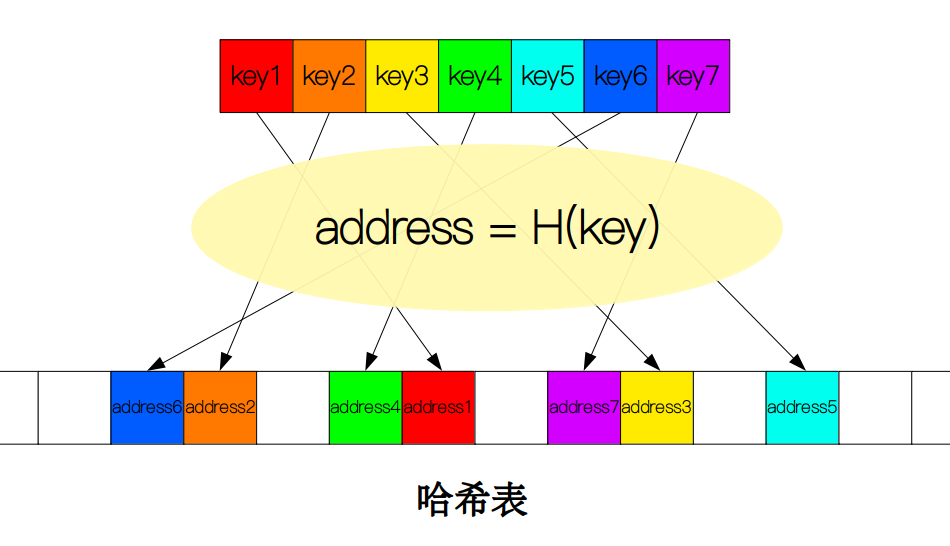
哈希函数
要想实现key到address之间的映射关系,我们需要借助一个特殊的函数,哈希函数(hash function)。哈希函数多种多样,但它们的功能都只有一个,那就是将不同的key均匀分散地分布在哈希表中,以达到便于查找的目的。最常见的,也是最简单的哈希函数就是取余操作,即H(key) = key mod m,其中m表示哈希表的长度。
举个例子,假设哈希函数H(key) = key mod 7,当key为 32 时,计算出的结果等于 4,这里的 4 就代表由哈希函数计算出的哈希地址address,当然这里的地址并非计算机的物理地址,只是为了方便而举的例子而已。在哈希表中我们就在索引为 4 的位置记录下 32。下次查找的时候,我们就可以通过哈希函数计算出的地址然后直接访问表里的值了。
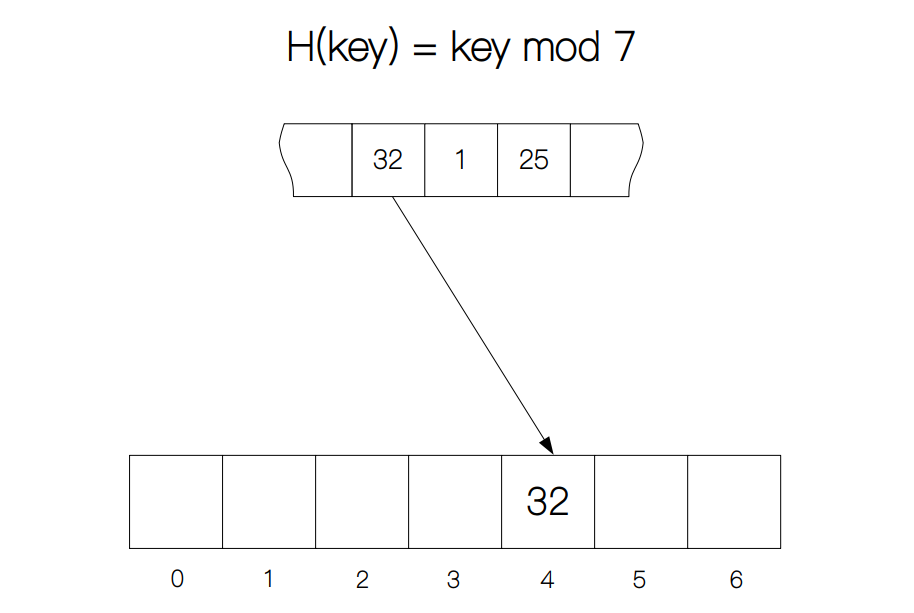
如果其他值 key 通过哈希函数计算得到了相同的地址,这就会造成一种现象叫做冲突(collision),比如 25 mod 7 也等于 4,造成了 25 不能够直接存储在索引为 4 的位置。为了解决冲突的问题,我们需要采用一些机制来保证那些冲突的元素能够存储在正确的位置,下面就来分别介绍一下几种主要的处理冲突的方法。
参考
https://infinityglow.github.io/study/algorithm/time-space-tradeoff/hashing/
https://www.cnblogs.com/yahuian/p/hash-table.html